RefRad2D dataset.
RefRad2D contains 760,409 CT and 256,197 MR image–report pairs derived from clinical routine.
From these we automatically build two task-specific subsets: RefRad2D-Grounded, with 236,157 grounded slice–text
pairs (217,692 CT, 18,465 MR), and RefRad2D-VQA (~9.6M QA pairs), generated with Gemma 3 (27B) as five QA pairs
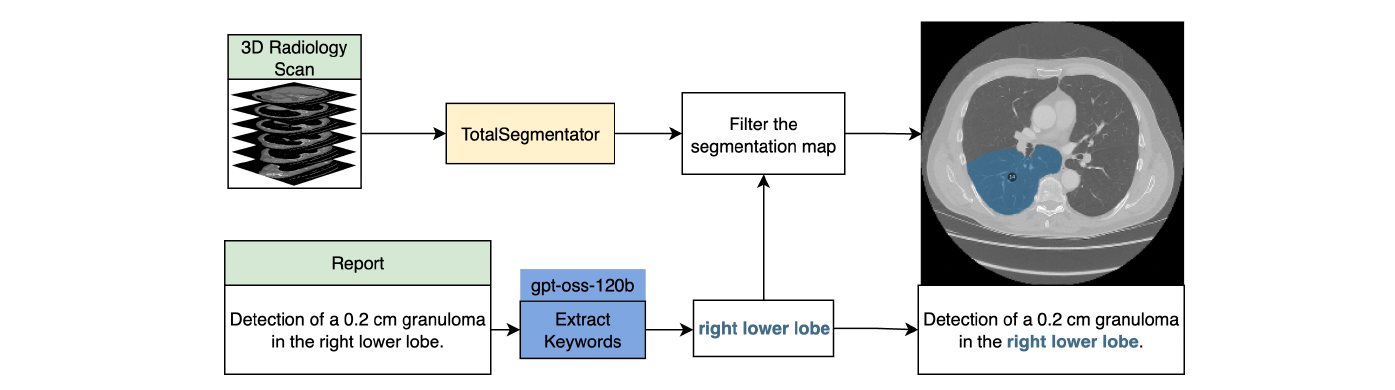
per image from clinical findings plus three from slice metadata. Grounding labels are obtained by running TotalSegmentator
on the 3D volumes (harmonized to a unified schema of C = 121 anatomical classes) and matching the resulting
masks to anatomical mentions extracted from each report.
Architecture.
RadGrounder builds on PaliGemma 2 (3B), comprising a SigLIP-So400m vision encoder and a Gemma-2B language
decoder. The model processes an image into visual tokens that are concatenated with text tokens and processed autoregressively.
We investigate two grounding strategies on top of this foundation.
Bounding-box detection.
We treat spatial grounding as a text-generation task, extending the vocabulary with coordinate tokens (512 bins) and
class-identifying tokens. The model generates a structured sequence
<p bbox> [LOC] id=<segID> KEYWORD </p>, where [LOC] denotes the box coordinates and
id maps to the unified anatomical schema. A class-wise merging strategy resolves multiple instances of the same organ.
Segmentation head.
We also explore pixel-level grounding via a lightweight mask decoder following VividMed and SAM. When the model emits a
</seg> token, its hidden state is projected into a 256-dim prompt that drives a Two-Way Transformer over the
image embeddings to produce a binary mask. The model is trained end-to-end with an autoregressive cross-entropy loss
Ltxt; the segmentation variant adds an auxiliary loss
L = Ltxt + λseg(Lfocal + Ldice).
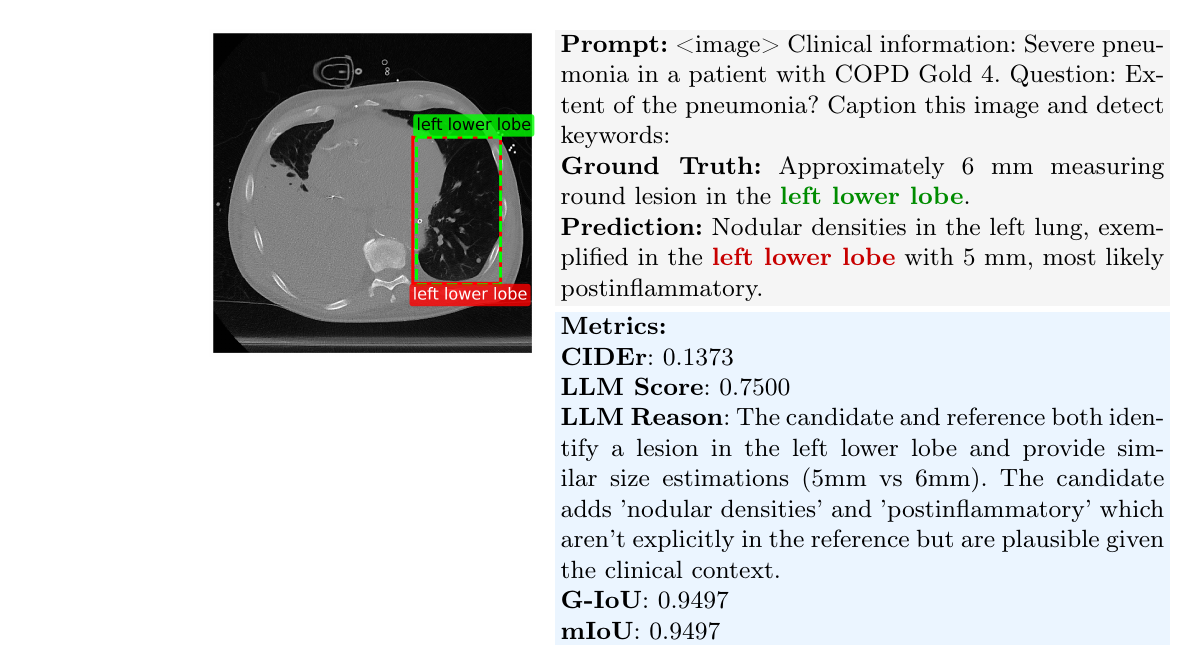
Evaluation: LLMScore & G-IoU.
Because n-gram metrics (e.g., CIDEr) struggle with the semantic equivalence of medical text, we introduce LLMScore,
an LLM-as-a-judge metric (Gemma 3 27B) on a 5-point scale. Validated against three radiologists, it reaches an
inter-annotator agreement of Krippendorff's α = 0.958 and a Pearson correlation of r = 0.977 with
mean human scores. We additionally propose Grounding-IoU (G-IoU), which jointly measures spatial and semantic fidelity by
weighting per-entity spatial IoU with the cosine similarity of the entity text embeddings.